Paper Dissection : PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
In this post I will be discussing about a paper on new paradigm which when applied to Transformer based Sequence-to-sequence models has equalled or exceeded the SOTA on 12 downstream summarization datasets. It also has worked well on low resource abstractive summarization tasks.
Introduction and Motivation
Pre training and finetuning the recently famed Transformer based Sequence-to-sequence models have improved the accuracy of several downstream tasks such as text classification, machine translation etc on text data. However, tailoring of this self supervised learning for a downstream task have not been explored. In this paper : PEGASUS which stands for Pre training with Extracted Gap-sentences for Abstractive SUmmarization Sequence-to-Sequence models, the authors propose a new pre training paradigm which when trained using a base transformer model has exceeded the SOTA score measure on 12 downstream low summarization tasks measured by ROGUE scores.
Pre-training Methodology and Objective
Pre-training Methodology
Currently for transformer models like BERT which is a MLM (Masked Language Model) where a token in a sentence is masked while pretraining, such a model trained with this MLM yields unsatifactory results on summarization. A new self-supervised training objective where a sentence itself is masked and generating this gap sentences on a transformer encoder-decoder model serves the purpose of modelling the transformer for Abstractive summarization.
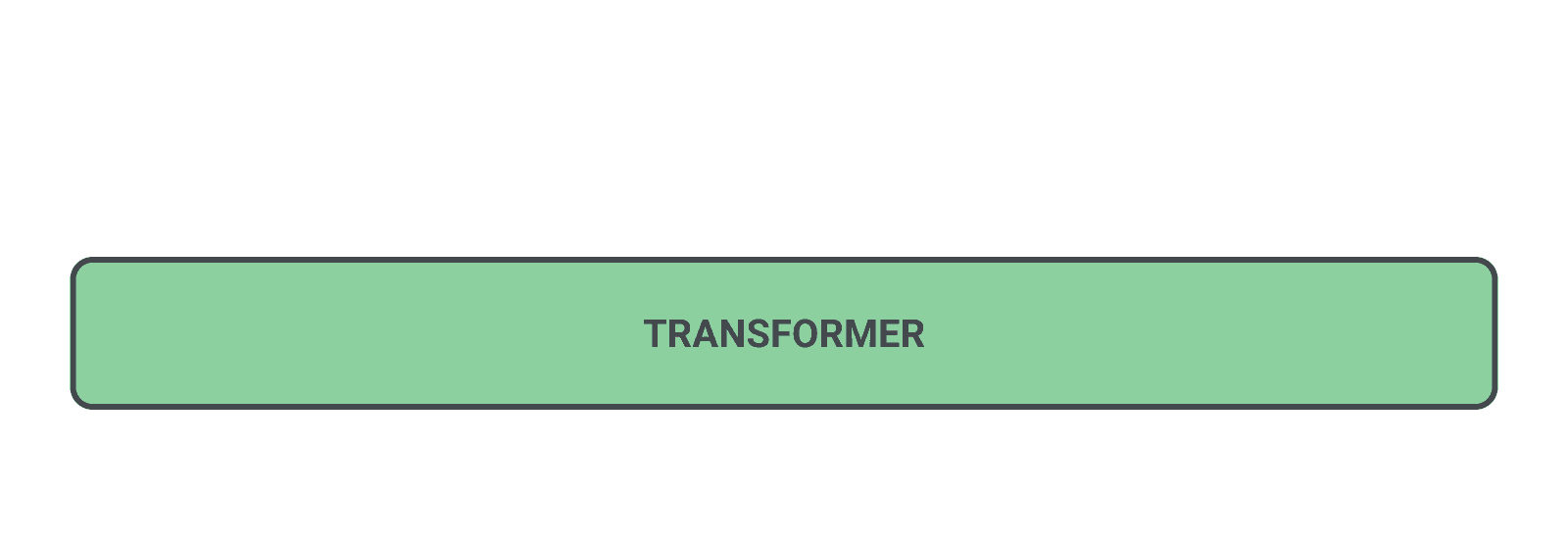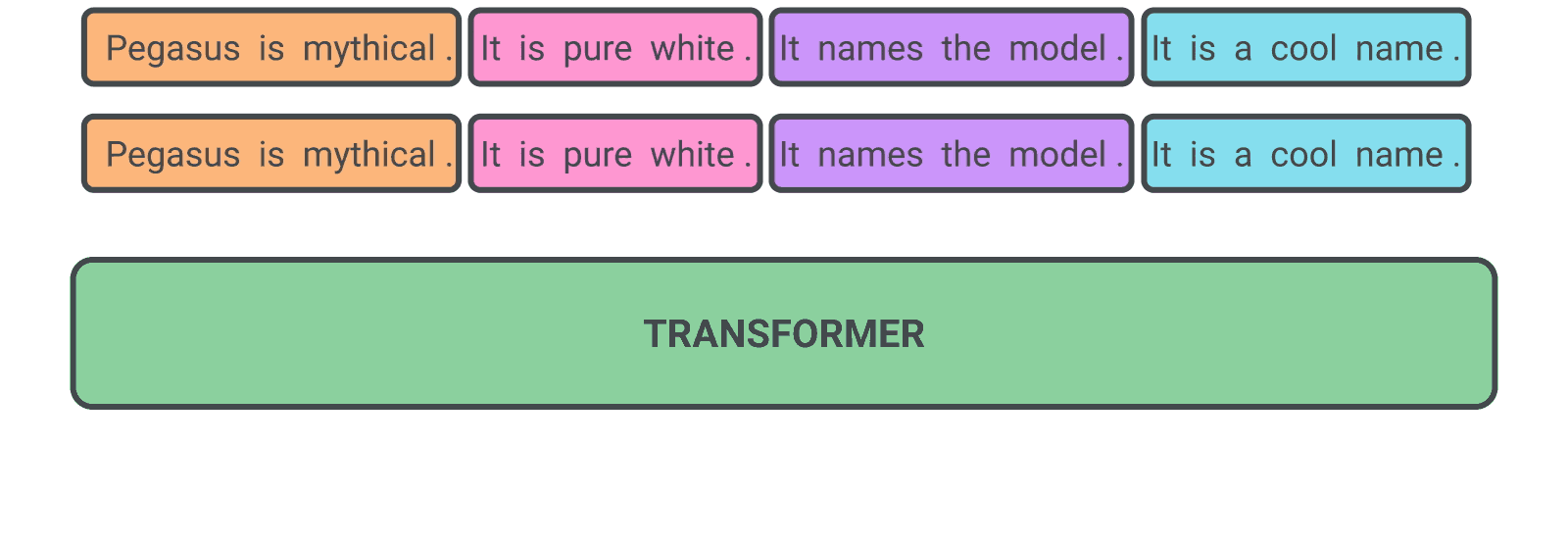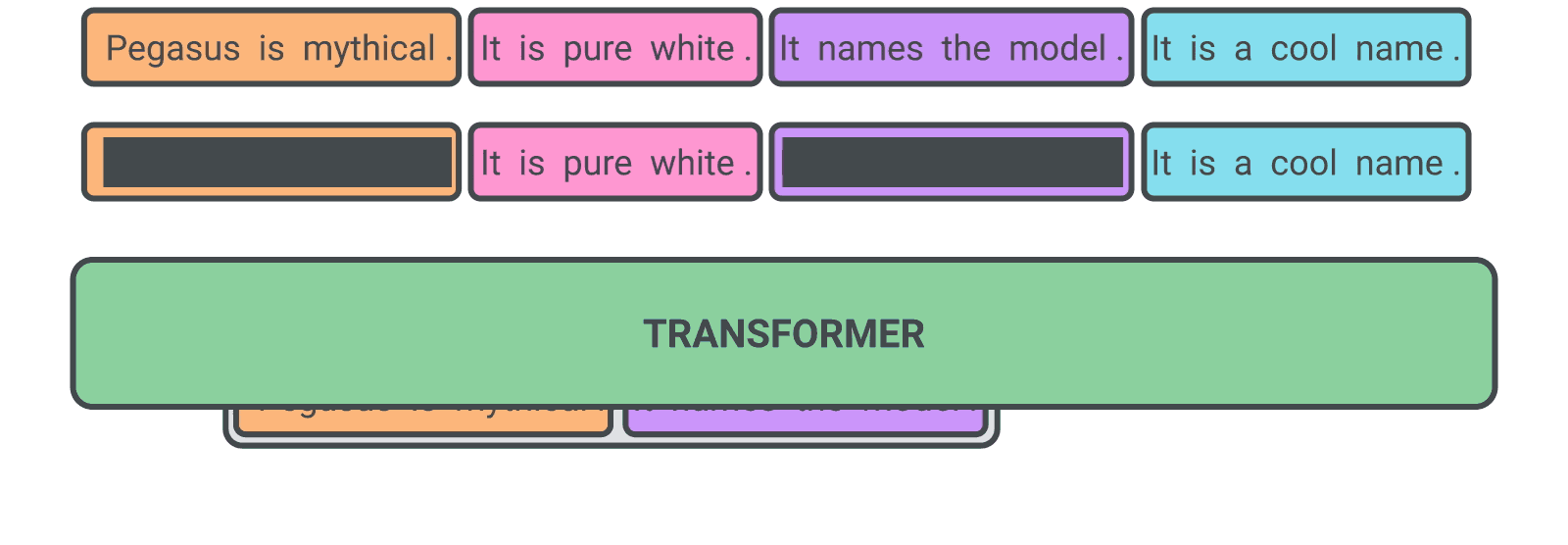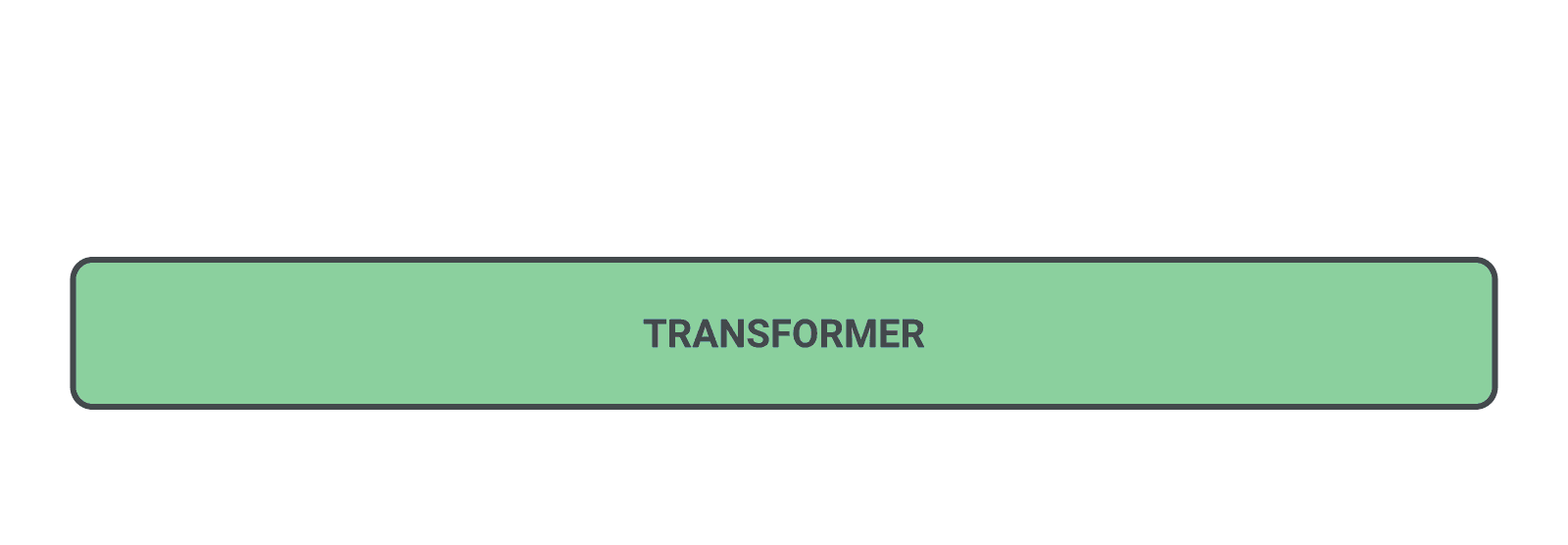
Figure 1. GSG (Gap Sentence generation) objective for pretraining transformer models. Credit : GoogleAI blog
Pre-training Objective
For comparision along with the GSG, the authors also have used the masked language modelling objective (masking some tokens) in conjuction, isolation as well. In GSG, the gap sentence which are masked are represented as [MASK1] for the model and the masked sentence form a pseudo summary for the doc. Depending upon the \(GSR\) (Gap sentence ratio) sentences are selected to be masked. The document is represented by \(\boldsymbol{D}\) = \(\{x_i\}_n\) which comprimises of \(\boldsymbol{n}\) sentences and let \(\boldsymbol{m}\) be the number or sentences to be masked.
There are three important ways we can choose a sentence for GSG
- Random - Selecting \(\boldsymbol{m}\) sentences uniformly across the document.
- Lead - Select the first \(\boldsymbol{m}\) sentences.
- Principle - Select top \(\boldsymbol{m}\) scored sentence on a metric - (ROGUE is used here)
It is observed that a principled way of selecting the sentences yielded better results. Below is the algorithm used to select the sentence \(\boldsymbol{s_i}\) from document \(\boldsymbol{D}\).

Figure 2. Greedy Algorithm to maximise the ROGUE-F1 Score
This algorithm for each \(\boldsymbol{m}\) steps calculates the ROGUE1-F1 score between the - \(\boldsymbol{(S \cup \{x\}_i)}\) (Which represents the union of all the previously selected sentences and the \(\boldsymbol{i}\)th selected sentence) and the Document \(\boldsymbol{D}\) not containing those sentences : (\(\boldsymbol{D}\) \ \(\boldsymbol{(S \cup \{x\}_i)}\) ). After getting the scores, the \(\boldsymbol{k}\)th sentence which maximises the ROUGE1-F1 is selected and inserted in the Set \(\boldsymbol{S}\). When selecting n-grams (here 1 gram), the idea is to select the unique 1-gram.
Additonally, as earlier mentioned \(15\)% of the token are replaced as [MASK2]. However, MLM does not improve the downstream task and hence it was avoided in the final training.
For pretraining the models, the authors used two corpus :
- C4 - Collosal and clearned version of Common crawl webpages - 350M Webpages - (750GB)
- HugeNews - Dataset of collected news from 2013-2019 (1.5TB)
Experiments and Results
For downstream tasks, if there were no split : 80/10/10 (training/validation/testing) was the ratio used for modelling. For ablation study, the model was intially trained on an architecture having 223M parameters - PEGASUS\(_{BASE}\) which had L = 12 (No. of transformer layer = 12), H = 768 (No. of embedding dim), A = 12 (No. of self attention head) and F = 3072 (Feed Forward layer size) which was tested on 4 of 12 datasets with a batch size of 256 and then moved to scale it to a larger model PEGASUS\(_{LARGE}\) which had H = 1024, L = 16, F = 4096 and A = 16 with a batch size of 8192. Sinusoidal positional encoding is used for maintaining the token postion. Adafactor with square root learning decay along with a dropout of 0.1 is used for training these models.
For ablation study, greedy decoding was used and while training PEGASUS\(_{LARGE}\) the paper switches to Beam search with a length penalty \(\alpha\).
Ablation of PEGASUS\(_{BASE}\)
Some of the Ablation outcomes : :
- For training PEGASUS\(_{LARGE}\) large Ind-Orig (Individual score - Orignal implementaion) sentence selection was used.
- GSR (Gap sentence ratio) for PEGASUS\(_{LARGE}\) was set at 30%.
- No MLM training was used for PEGASUS\(_{LARGE}\).
- Effect of Vocabulary : In comparing BPE (Byte pair encoding) and SentencePiece Unigram, for non news articles unigram worked better. For PEGASUS\(_{LARGE}\) Unigram with 96K vocabulary size was used.
Larger model Results
The larger model was trained for 500k steps having 528M parameters while adapting the outcome of ablation study, these were the results. Best ROUGE numbers on each dataset and numbers within 0.15 of the best numbers are bolded.
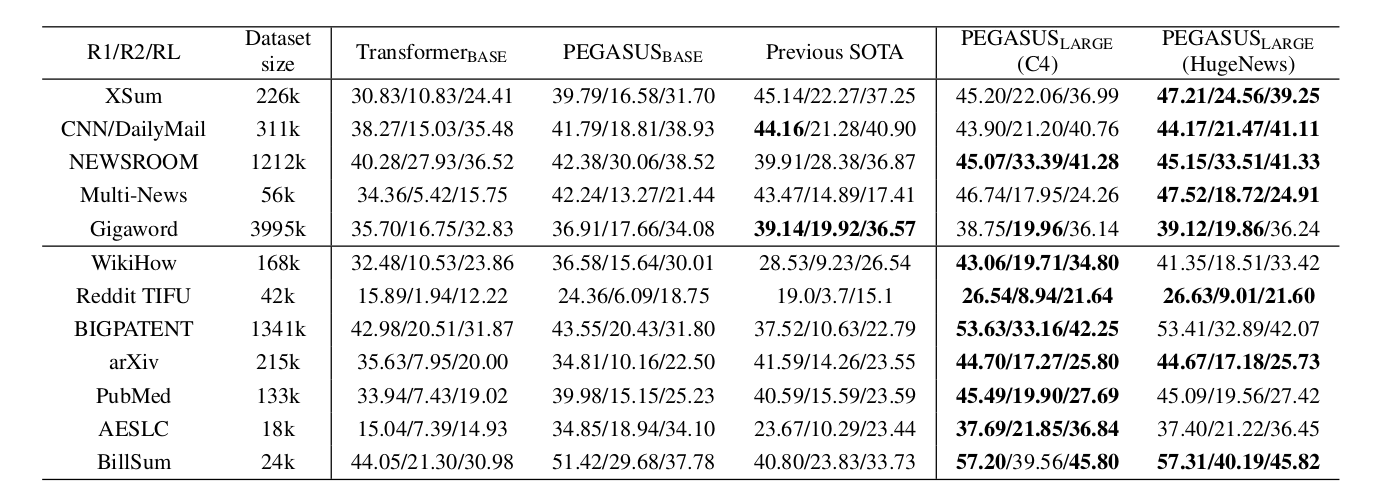
Figure 3. Results of PEGASUS\(_{LARGE}\) on all downstream summarization tasks compared with previous SOTA.
For further deep understanding of the paper please refer the original paper : here