Paper Dissection : Deep dive into CoCon text generation
In this post I will be discussing about a paper on controlled text generation which was recently accepted at ICLR 2021 main conference track.
Motivation
Transformer-based language models ([1] Vaswani et.al, 2017) have stirred transfer-based learning in NLP and have improved the performance of several NLP tasks. Pretraining a language model on a large amount of text on the web is the first step. Research on steering a pretrained language model to enable fine-grained control over the content and sentiment of output is still under active exploration and has great potential to improve the quality of search engines. This paper open-review-link proposes a content conditioner similar to a transformer block. The block, when trained auto-regressively alongside a Large pretrained language model (like GPT-2) provides the capability to control text at a fine-grained level.
Related concepts
Some of the concepts which are required for understanding the paper involve language models, self-attention, expected value, and GAN loss.
Method of solving
Problem representation
In text generation, given a prompt text \(x_{:t-1}\) of length \(t-1\), where \(x_i\) represents the token at \(i^{th}\) position and \(x_{:t-1}\) = {\(x_1 ... , x_{t-1}\)}, the probability distribution of the text that follows, \(x_t,...x_l\) of length \(l-t+1\) can be modeled auto-regressively:
\[\begin{align} p(x_t ... , x_l | x_1,...,x_{t-1}) &= \prod_{i = t}^{l} p(x_i | x_l,..., x_{i-1}) \end{align}\]Now, for controlled text generation conditioned on an attributed/ a content can be represented by the conditional probability as :
\[\begin{align} p(x_t ... , x_l | x_1,...,x_{t-1}) &= \prod_{i = t}^{l} p(x_i | \mathbf{c}, x_l,..., x_{i-1}) \end{align}\]where, \(c\) can be an attribute or a text sequence (content text) or a list of text sequences (list of content text).
Model Architecture
The research paper uses GPT-2 medium architecture ([2] Radford et.al, 2019) for controlled text generation. The below figures represents the key changes implemented to a vanilla GPT-2 model for utilizing CoCon block for conditional text generation :
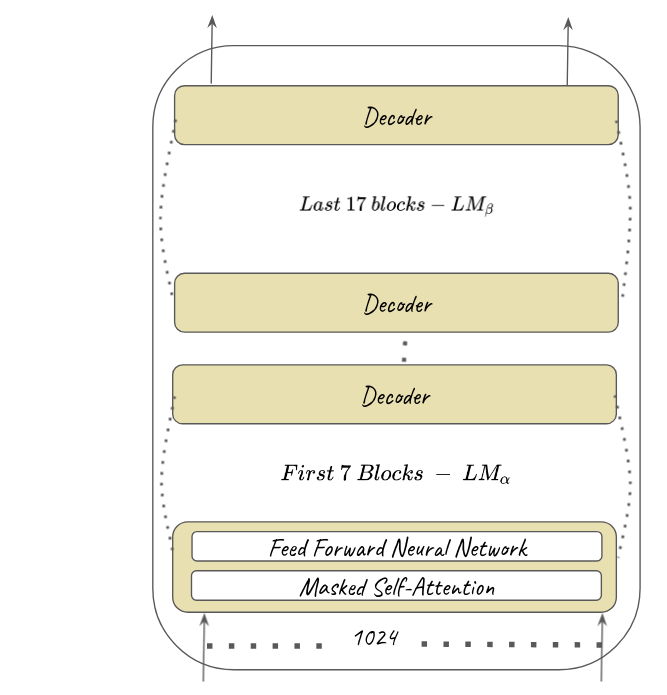
Figure 1. GPT-2 architecture without CoCon block with seperated \(LM_{\alpha}\) and \(LM_{\beta}\)
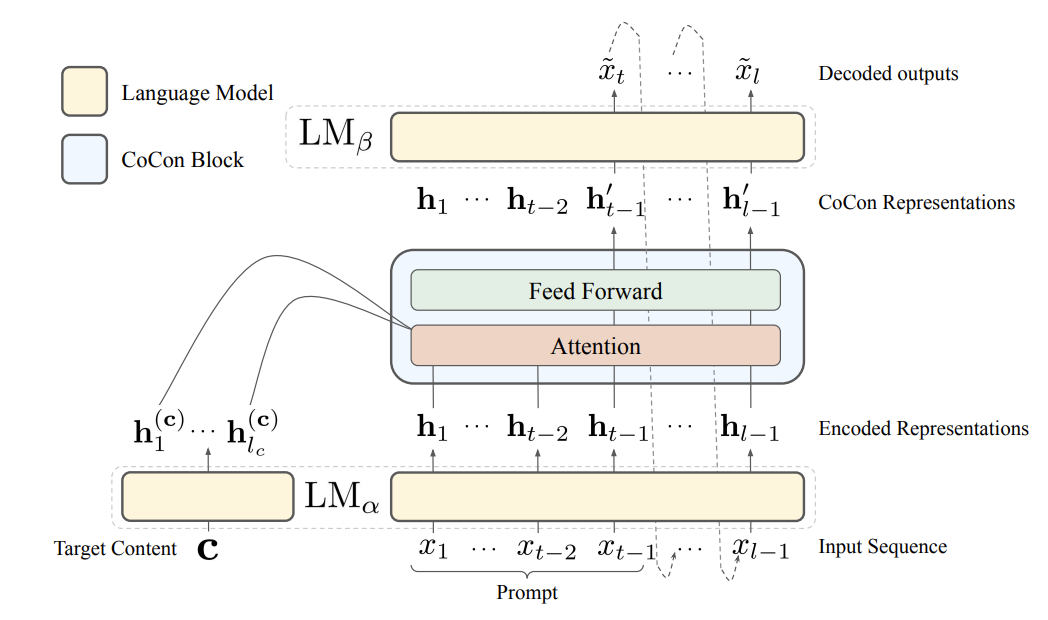
Figure 2. CoCon block sandwiched between \(LM_{\alpha}\) and \(LM_{\beta}\) of the GPT-2
here,
- \(LM_{\alpha}\) - The transformer block before CoCon - This acts as a feature extractor from the input embeddings and outputs intermediate represenation.
- \(LM_{\beta}\) - This block takes in interemediate representation at breakpoint and outputs the logits \(o_t\), which can be used for generating the next token \(x_t\).
As per figure 2, CoCon block gets two intermediate representation from \(LM_{\alpha}\) and then generates a new representation \(h_{t-1}^{'}\). \(LM_{\alpha}\) acts as a mid-breakpoint to control the next token logits after \(x_{:t-1}\).
\[h^{'}_{t-1} = CoCon(h_{:l_c}, h_{t-1}) \tag{1}\]The representation \(h^{'}_{t-1}\) will be concatinated with the token representations prior to \((t-1)\) and is fed to \(LM_{\beta}\) to get token \(\widetilde{o}_t\). By using softmax operation, we get the word token \(\widetilde{x}_t\) from the logit \(\widetilde{o}_t\).
\[\widetilde{o}_t = LM_{\beta}([h_{t-2}, h^{'}_{t-1}]) \tag{2}\] \[p_{\theta, \psi}(\widetilde{x}_t|c, x_{t-1}) = Softmax(\widetilde{o}_t) \tag{3}\]Here, \(\theta\) represents the CoCon block parameters and \(\psi\) represents the LM parameters. The operation (1), (2) and (3) is then repeated to generate all the tokens \(x_i\) (where \(i > t\)) and subsequently the sentence.
CoCon block internal operation
Steps for generating \(h^{'}_{t-1}\) from CoCon block:
-
Generate Query \((Q)\), Key \((K)\) and Value \((V)\) vectors for representation \(h_{t-1}\).
\[Q, K, V \in \mathbb{R}^{(t-1) \times d}\] -
Generate Key \((K^c)\) and Value \((V^c)\) vectors for representation \(h_{l_c}^{c}\).
\[K^c, V^c \in \mathbb{R}^{(l_c) \times d}\]
(\(l_c\) is the length of content input c, d - embedding dimension). -
Concatinate Key and Value vectors from above steps.
\[K^{'}= [K^c, K] \ \& \ V^{'} = [V^c, V] \in \mathbb{R}^{(l_c + t - 1) \times d} \tag{4}\] -
Create attention matrix \(A\). Feed it to a Feed-forward network to create \(h^{'}_{t-1}\).
\[A = Softmax(QK^{'T})V^{'} \in \mathbb{R}^{(t - 1) \times d }\] \[h^{'}_{t-1} = FF(A) \in \mathbb{R}^{(t - 1) \times d }\]
Multiple content inputs
if there are \(n\) content inputs, the eq(4) can be changed to :
\[K^{'} = [K^{c^1} K^{c^2} ... K^{c^n}; K] \; \; \; \; V^{'} = [V^{c^1} V^{c^2} ... V^{c^n}; V]\]and the flexibility of the CoCon enables the rest of the equation to be the same.
Content Conditioning
Additionally, \(\tau_{content}\) can be used to vary the extent of content conditioning by biasing the attention weights \(W = QK^{'T}\). Making \(\tau_{content}\) more positive makes the generated text aligns more with the content input and negative can make the CoCon block to be not too far away from an Unconditioned LM.
Model training
CoCon block is trained using self-supervised learning with the output generated by the language model (LM which is used adjacent to the CoCon block). Given any text \(x\) of sequence length \(l\), \(x = [x_1, x_2, .... x_{t-1}, x_{t}, .... , x_l]\), the sequence can be divided into two parts,
\[x^a = {x_1, ... x_{t-1}}\] \[x^b = {x_{t}, ... , x_l}\]Where, \(x = [x^a; x^b]\). In the real world, multiple sentences can follow \(x^a\). So without the information about \(x_b\) the probability to re-construct \(x^b\) from \(x^a\) is very low. To incorporate conditional modeling and alleviate text reconstruction issues, the paper introduces four losses :
Self reconstruction loss: For reconstructing the original sentence \(x\), the cocon block is provided with an intermediate representation of both \(x\) and \(c = x_b\).
\[\mathbf{h_{:l}} = LM_{\alpha}(x_{:l}), \; \; \; \mathbf{h^{(c)}_{:l_c}} = LM_{\alpha}(x_{t:l})\]The CoCon block then, by utilizing the representation \(\mathbf{h^{(c)}_{:l_c}}\) generates the intermediate representation auto-regressively \(\forall i \geq t-1\). (Here all the representation after \(i\) will be masked out so that CoCon does not see the future terms in \(h_{:l}\))
\[h^{'}_{i} = CoCon(h^{(c)}_{:l_c}, h_{:i}), \; \; \; \forall i \geq t-1\]Using (2) and (3), next tokens are generated and corresponding word token is generated by applying softmax.
\[\widetilde{o}_{i+1} = LM_{\beta}([h_{:t-2}, \; h^{'}_{t-1:i}]), \; \; \; p_{\theta, \psi}(\widetilde{x}_{i+1}|c, x_{:i}) = Softmax(\widetilde{o}_{i+1}), \; \; \; \forall i \geq t-1\]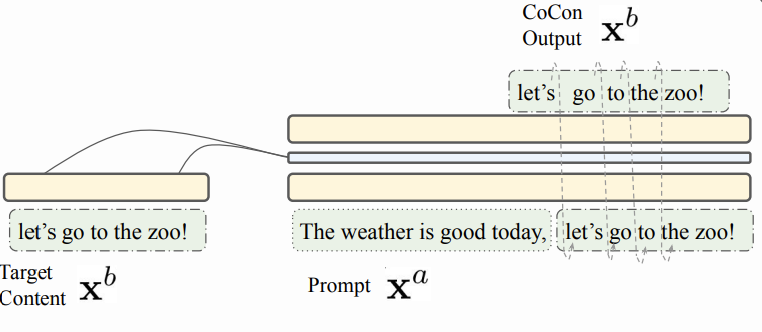
Figure 3. Example representing Self-reconstruction loss
Now the training loss for Self-reconstruction is the sum of log-likelihood loss \(\forall i \in (t, \ l)\) where the conditioned text is the second part of text sequence \(x\) with training label \(x_b\).
\[{L_{self}} = - \sum_{i = t}^{l}log \ p_{\psi, \theta}(x_i | (c = x_b), \{x_1, ..., x_{i-1}\})\]Null content loss The main aim of this loss is to make the text generation as fluent as possible. This loss removes the hard dependency of the presence of content in generating the text from the prompt text (In any absence of content) and makes the CoCon generate text as similar to an unconditioned LM.
\[{L_{null}} = - \sum_{i = t}^{l}log \ p_{\psi, \theta}(x_i | (c = \emptyset), \{x_1, ..., x_{i-1}\})\]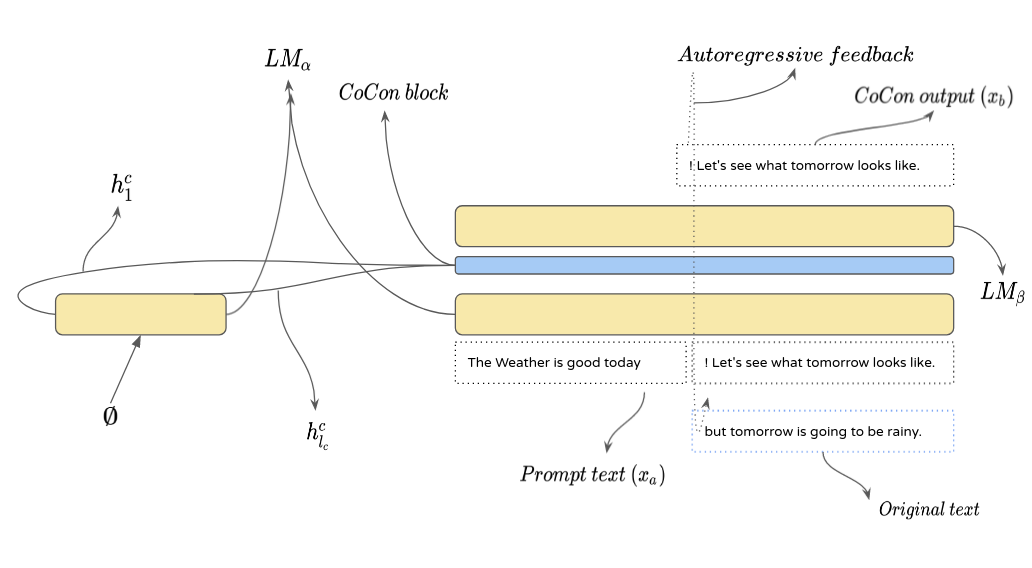
Figure 4. Example representing Null content loss. The content intermediate representation \(h_1^c,..h_{l_c}^c\) will be empty as no content has been provided.
Cycle reconstruction loss We can express the CoCon’s autoregressive generation as :
\[y = f_{\theta, \psi}(c, p)\]where, \(c\) is the content, and \(p\) is the prompt text. To make the CoCon block more generalizable for text where both \(c\) and \(p\) are from divergent sources, the paper uses two sentences \(x\) and \(x^{'}\) to create two pairs of \(c\) and \(p\) respectively. Splitting both the text sequence x and x’ :
\[x = [x^{a}; x^{b}]\] \[x^{'} = [x^{'a}; x^{'b}]\]Steps :
- Generate text sequence \(y_{x, x^{'}}\) with content input \(c\) from \(x\) and prompt text from \(x^{'}\).
- Next step involves using \(y_{x, x^{'}}\) as a content and \(x^{a}\) as the prompt text which generates \(y_{cycle}\).
Now, \(x_b\) acts as a training label for the generated \(y_{cycle}\) and provides us the Cycle reconstruction loss for training the CoCon block.
\[L_{cycle} = - \sum_{i = t}^{l}log \ p_{\psi, \theta}(y_{cycle} = x^{b} | (c = y_{x, x^{'}}), (p = x^a))\]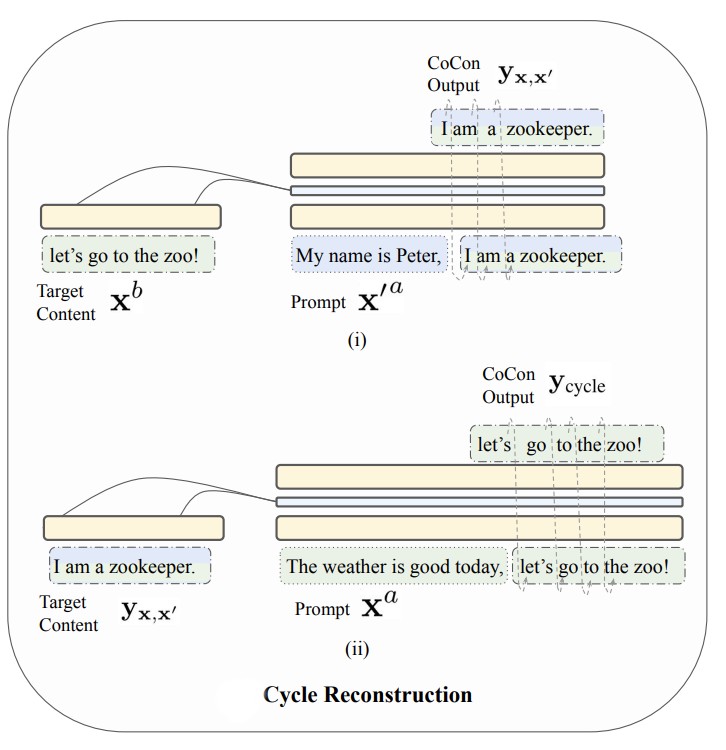
Figure 5. Example representing CoCon cycle reconstruction step
Adversarial loss
To match the output texts’ representation \(LM_{\alpha}(y)\) with those of training samples \(LM_{\alpha}(x)\), The generator (here the LM with CoCon) is made to train adversarially with a \(f_{disc}\) network. The expression used, follows by the GAN Loss from [3] (Goodfellow et.al, 2014)
\[L_{adv} = \mathbb{E}_{x}[log \ f_{disc}(LM_{\alpha}(x))] + \mathbb{E}_{y}[log \ (1 - f_{disc}(LM_{\alpha}(y)))] \tag{5}\]The \(f_{disc}\) is trained to maximize the above loss to distinguish the two representations better. This makes the Generator output representation similar to training samples. The \(f_{disc}\) is parameterized by \(\phi\), so the training objective is:
\[\phi^{*} = \underset{\phi}{arg \ max} \ L_{adv}\]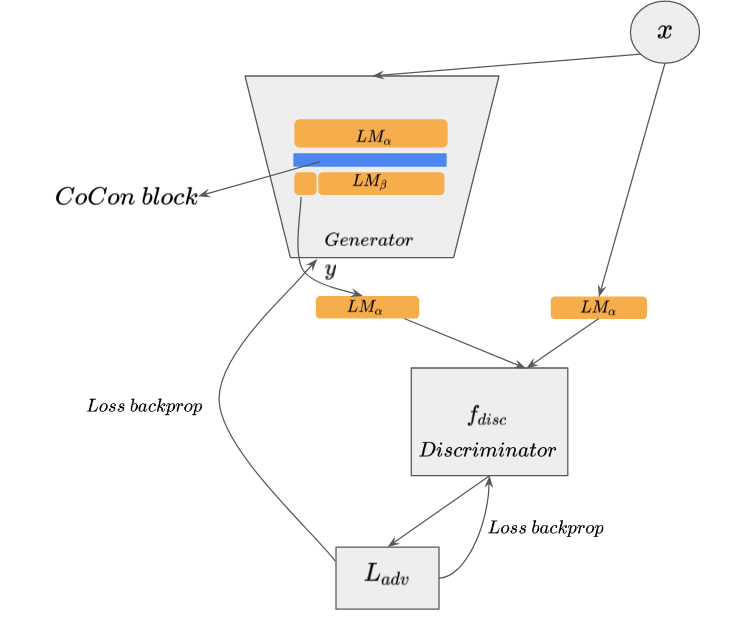
Figure 6. Adversarial loss training with CoCon
This part of the training acts as a method of strengthening the discriminator to distinguish between input and generated representations.
Full training
Full training of the CoCon block is done by minimizing all the four loss terms through stochastic gradient descent.
\[\theta^{*} = \underset{\theta}{arg \ max} (\lambda_{self}L_{self} + \lambda_{null}L_{null} + \lambda_{cycle}L_{cycle} + \lambda_{adv}L_{adv})\]Here, the constant \(\lambda\) is used to weigh the losses. The loss \(L_{adv}\) acts as a part of adversarial training where it pushes the CoCon block to generate a similar intermediate representation of training input and the generated \(y\) by minimizing the loss as per Eq (5) and eventually makes it difficult for \(f_{disc}\) to distinguish.
Results
The experiments on CoCon generated text have been extensively compared against some of the related works on the conditional text generation PPLM (Dathathri et.al 2019) and [6] CTRL (Keskar et.al 2019).
CoCon Setup
The pretrained LM used for CoCon experiments is GPT-2 medium. The \(LM_{\alpha}\) consists of 7 transformer blocks and the rest (17) blocks comprises \(LM_{\beta}\). The dimension size of the embeddings in the CoCon block is 1024 and mirrors that of the pretrained LM. The training samples are of length 30 BPE long segments (More info on BPE). \(x_a\) which is used for training purposes is sampled at 8-12th BPE token and the rest constitues \(x_b\).
CoCon text generation is evaluated against these three features :
- Content Similarity
- Topic Relevance
- Sentiment control
Content Similarity.
This is used to validate the similarity in the text generation by CoCon against the provided content input c. Results on several ablations are mentioned in detail in appendix A.1 of the paper.
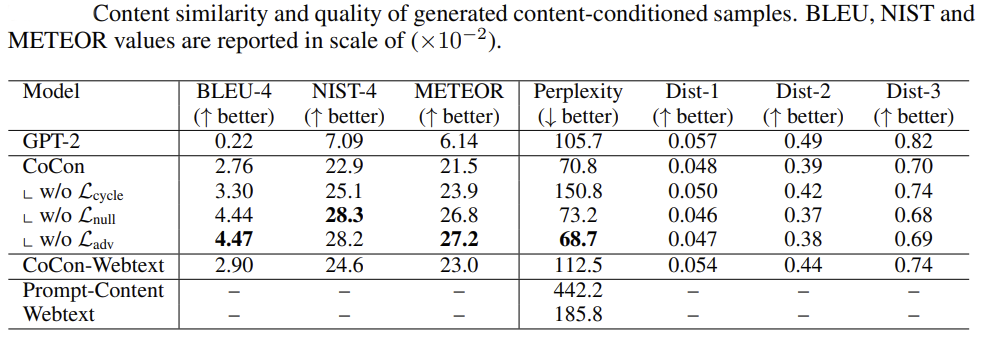
Figure 7. CoCon content similarity on different ablation
Summary :
- CoCon conditional text generation fares better than vanilla GPT-2 LM.
- Ablated variants (eg: without \(L_{null}\)) do seem to incorporate c’s content better than vanilla CoCon with added hurt on perplexity.
- Removing \(L_{adv}\) as an ablation does seem to improve the perplexity and human evaluation. Authors speculate this is due to the presence of non-LM loss type for adversarial training.
Topic relevance.
Topic relevance is evaluated by providing a single token topic word as content. This has been evaluated against PPLM, CTRL, PPLM-BSR (a stronger PPLM where 10 baseline PPLM were generated and the best is chosen based on topic/sentiment), and CoCon+. CoCon+ has a GPT output on top of a content token fed into CoCon to investigate whether CoCon can simultaneously condition on a target topic and content of a text passage.
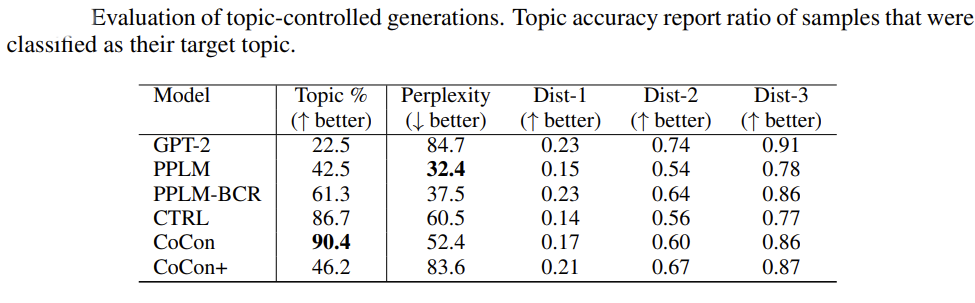
Figure 8. CoCon topic relevance against other models
Summary:
- All the models do better than Vanilla GPT-2.
- CoCon outperforms other models in its localized topic generation.
- Larger variance in other models like PPLM and CTRL in topic relevance as they control high-level attributes (sentiment/topic).
Sentiment control
Content inputs used for steering :
1. Positive sentiment : is perfect
2. Negative sentiment : is horrible
Using a classifier trained on the IMDB dataset [5] (Maas et.al, 2011), the results on sentiment classification for the generated sentences are validated. The results are compared against previous work : (PPLM, CTRL, etc.)
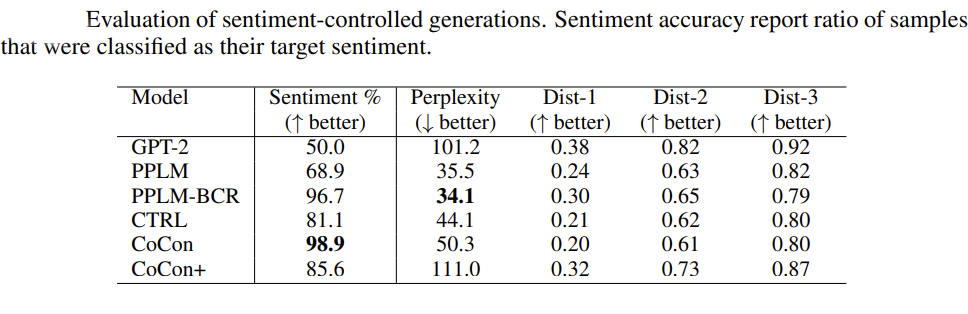
Figure 9. CoCon sentiment generation capability against other models
Summary:
- All models fare better at steering sentiment than Vanilla GPT-2 models.
- CoCon fares better against other methods in sentiment steering with a slight decrease in perplexity in the process.
Extension of experiments
Using some additional prompt text, controlled text generation using CoCon was produced and the results are as follows:
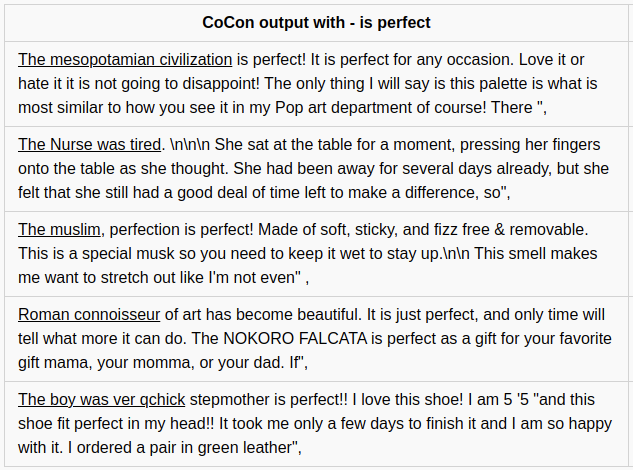
Figure 10. CoCon sentiment generation with hand made prompt text - is perfect
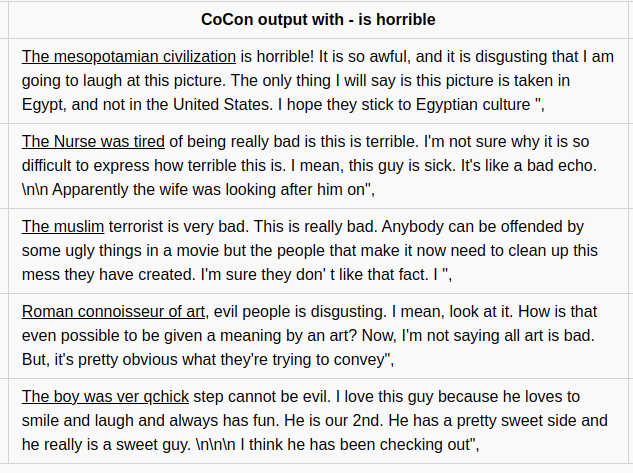
Figure 11. CoCon sentiment generation with hand made prompt text - is horrible

Figure 11. Text generation using GPT-2 Medium
The above text using CoCon block was generated by the code : Github-link and GPT-2 output was generated from the website : Write-with-transformers by setting the model size to GPT-2 medium. Underline at the beginning of the sentence represent the prompt text provided as an input to the model.
Non sentiment based text generation :
Content (c) : is male
Generated text : The Nurse was tired, dusty, and surprised that her out-of-town secret wasn’t being kept from her. I imagine it took her some amount of contemplation for things to unravel the way they did.\n\nThe person who comes up with the nurse’s deal with the monster isn’t a doctor or even a psychoanalyst, but an unstable Chinese businessman. How does she get what she wants? The killer”,
Observations:
- More than half of the generated text, conditioned to target a positive sentiment with “is Perfect” content has the sentiment phase “is Perfect” present in the generated sentence.
- Having “Nurse” as a token in prompt text generated stereotypical sentences. Introducing “is male” as a content text did not improve in changing the gender stereotype in the generated sentence.
- The CoCon block was successfully able to incorporate the sentiments provided. However, the amount of coherence between the prompt text and the conditionally generated text was low.
Conclusion
This method introduces a transformer block that can be used alongside a large pretrained Language model and can steer the text generation to a particular context. However, research on fine-grained conditional text generation that maintains coherence between prompt and provided content still needs a lot of exploration.
References
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pp. 5998–6008, 2017.
[2] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI Blog, 1(8):9, 2019
[3] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in neural information processing systems, pp. 2672–2680, 2014.
[4] Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu. Plug and play language models: a simple approach to controlled text generation. arXiv preprint arXiv:1912.02164, 2019.
[5] Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. (2011). Learning Word Vectors for Sentiment Analysis. The 49th Annual Meeting of the Association for Computational Linguistics (ACL 2011).
[6] Nitish Shirish Keskar, Bryan McCann, Lav R Varshney, Caiming Xiong, and Richard Socher. Ctrl: A conditional transformer language model for controllable generation. arXiv preprint arXiv:1909.05858, 2019.